Python3写入数据到csv文件中编码问题
本文共 1002 字,大约阅读时间需要 3 分钟。
本人在用python导出数据到csv的过程中,发现python3.5写中文字符到csv报错,
错误信息
UnicodeEncodeError: 'gbk' codec can't encode character '\u25ba' in position 494: illegal multibyte sequence 这和python2.的解决方法是不一样的,百度之后总结出来供大家互相学习。python3.的应该都可以借鉴。
1.出现UnicodeEncodeError 说明是Unicode编码时候的问题;
'gbk' codec can’t encode character 说明是将Unicode字符编码为GBK时候出现的问题; 此时,往往最大的可能就是,本身Unicode类型的字符中,包含了一些无法转换为GBK编码的一些字符。
解决方法:
指定文件编码为 gb18030with open('data.csv', 'a+', encoding = 'gb18030') as f: 运行程序,无报错。
此方法同样适用文件出现乱码的问题。开发csv文件,发现每行之间有空行存在,怎么办?
解决方案: 增加参数newline = '' with open('data.csv', 'a+', newline = '', encoding = 'gb18030') as f: 示例:
import csvdatas = {'name':'Allen','adress':'beijing','job':'python'}with open('data.csv', 'a+', newline = '', encoding = 'gb18030') as f: csvwriter = csv.writer(f,dialect=("excel")) csvwriter.writerow([ 'name', 'adress', 'job' ]) csvwriter.writerow([ datas['name'], datas['adress'], datas['job'] ]) 结果如下
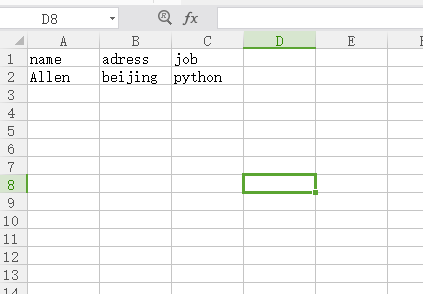
data.png
转载地址:http://zwaal.baihongyu.com/
你可能感兴趣的文章
Go 的 fake-useragent 了解一下
查看>>
创建topic——kafka源码探究之一
查看>>
【Laravel】Laravel 框架关键技术解析·读书笔记(一)
查看>>
ES6入门---let和const
查看>>
Codepen 每日精选(2018-4-10)
查看>>
git学习笔记
查看>>
Thinking——Debian On Windows初试
查看>>
看完你也想编写自己的 react 插件
查看>>
数据结构与算法:常见排序算法
查看>>
记录一次并发读取MongoDB的踩坑过程
查看>>
初识JavaScript EventLoop
查看>>
MVC是什么
查看>>
关于 emotion 初步使用的笔记
查看>>
PHP 怎样在同一个域名下两个不同的项目做独立的登录机制?
查看>>
SpringCloud(第 005 篇)电影微服务,注册到 EurekaServer 中,通过 Http 协议访问用户微服务...
查看>>
k-邻近算法(kNN)
查看>>
gulp基础和常用插件介绍
查看>>
开发之路(设计模式六:命令模式上)
查看>>
JavaScript:并发模型与Event Loop
查看>>
CSS揭秘之《条纹背景》
查看>>